
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- IS함수
- lob 7번
- mode함수
- 범용레지스터 #레지스터 #어셈블리 #ASM #리버싱 #어셈블리어 #EAX #ESP
- argc
- kostat
- wolfman to darkelf
- lob 9번
- lob
- ultra argv hunter
- pythoncli
- pythonexe
- 결측치
- argv
- kosis
- pyinstaller
- 빅데이터
- lob 10번
- 서니나타스
- 데이터형
- 써니나타스 1번
- 마크업 언어
- 포너블
- 써니나타스
- troll to
- R언어
- 쉘코드
- anxi0
- orge to troll
- 자료개방포털
- Today
- Total
ANX1-Z3R0의 불안극복(不安克服)
빅데이터 요점 정리 본문
빅데이터와통계01 1문제
-small data
-big data
-big data 특징 4가지
-정형 데이터와 비정형 데이터
정형데이터
관계를 가진 데이터들이 선이나 표따위로 표현된 유기적인 데이터
예) 클래스 다이어그램, 순서도
비정형 데이터
비구조화 데이터, 비구조적 데이터등 미리 정의된 데이터 모델이 없거나 미리 정의된 방식으로 정리되지 않은 정보
예) Log성 데이터(시간대별로 기록된), 텍스트, 사운드, 이미지
Small data(철저히 정형 데이터 위주)
간단한 정형 데이터
일 또는 월 단위 발생되는 데이터
300~10만 건의 기록으로 구성
샘플링 된 데이터로 통계적 지식 및 처리 필요
국내에서는 1999년 이전에 주로 활용
데이터에 대한 가설이 있음(예 : 정규성, 독립성 등)
통계분석 전문 소프트웨어, Excel 등으로 처리가능
활용 예 : “지역별 범죄유형 비율 및 차이”
Big data(정형 데이터 + 비정형 데이터)
IT 발전으로 보다 규모가 큰 TB 이상의 규모, 1천만~수십억 건의 3~10년 정형 데이터 활용
보다 정밀하고, 다양한 분석을 하고자 함
분석에서 서비스로의 확장에 관심이 큼
국내에서는 2013~현재까지 각광 받고 있는 분야
Big data의 특징(4V)
• Volume : 정형 데이터와 비정형 데이터를 다루다 보니 데이터 크기(Volume)가
상대적으로 이전보다 커짐
• Variety : 다양한 소스(데이터 발생 장소)에서 입수된 데이터를 활용
• Velocity : 데이터 발생 및 처리속도가 빨라짐
• Value : 상대적으로 매우 중요한 요소로 전통적으로 분석을 통한 Insight에서
실행(Action)을 통한 기업 및 고객의 가치 창출이 가능하다는 사항임
비정형 데이터 예시
• Log : 이산형/연속형, Web Log, Machine Log, 계량기
• Text : 소셜 미디어, 콜센터 통화 음성을 텍스트로 변환한 데이터
• Sound : 일상생활에서의 데이터, 공장/건설현장/기계에서 나오는 진동 및 소리
• Image : 사진, 얼굴 표정
• Video : CCTV
문제1. 입사지원을 위해 웹페이지에 접속해서 개인신상 정보와 자기소개서를 입력할 때 관련있지 않은 데이터는?
①정형 ②비정형 ③텍스트 ④로그
문제2. 다음중 비정형데이터는?
①사운드 ②매출액 ③거주지 ④소득수준
문제3. 빅데이터의 특징인 4V에 해당되지 않는 것은?
① Volume ② Variety ③ Velocity ④ Visibility
(1) 4 , (2) 1 , (3) 4
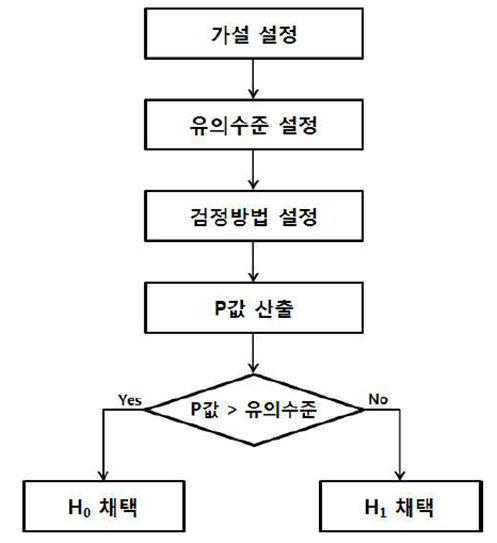
가설검정 4문제 - 어렵습니다 이해가 안되면 여기로....
-가설검정의 뜻, 귀무가설, 대립가설의 정의
-유의확률, 유의수준
-Boxplot(그림을 보고 뜻을 알면 됨)
-가설검정 분석 모델(빈도, 상관,카이제곱,t검정)
가설검정
모집단에 대한 통계적 가설을 세우고 표본을 추출한 다음, 그 표본을 통해 얻은 정보를 이용하여 통계적 가설의 진위를 판단하는과정
•귀무가설 :
현재까지 주장되어 온 것이거나 기존과 비교하여 변화 혹은 차이가 없음을 나타내는 가설이다. (같다, 차이가없다 등)
•대립가설 :
표본을 통해 확실한 근거를 가지고 입증하고자 하는 가설로서 연구가설이라고도 한다.
예: 성별에 따른 행복지수는 차이가 없다(같다) : 귀무가설
: 성별에 따른 행복지수는 차이가 있다 : 대립가설
1종오류 : 귀무가설이 진실임에서 불구하고 기각할 오류
2종오류 : 귀무가설이 거짓임에도 채택하는 오류
유의수준 : 제1종 오류를 범할 최대 허용치 (내가 정하는 값, 실수할 수도 있는 범위)
통계학적으로 유의수준을 보통 0.05, 0.01, 0.001 중 하나를 채택함
5%, 1%, 0.1% 이하로 작으면 그 일은 일어나지 않는다는 뜻
예) 백조는 흰게 맞는데, 검은 백조를 찾다보니, "잉크를 뒤집어 쓴 백조(오류)"를 찾아버렸네? - 유의수준에 포함시킴
유의확률(p-value) : 귀무가설이 참인데도 불구하고 이를 기각할 확률 (계산 된 값) , 잘못된 의사결정을 할 확률
예) 유전적으로 진짜 검은 백조를 찾은거지, 내가 정한 5%를 넘어버린 거야! - 데이터가 신빙성이 없게 됨.
따라서 대립가설을 뒷받침하기 위해 모은 데이터의 유의수준을 0.05로 정했다면 유의확률(p)이 0.05보다 적게 나와야 하며 결국 귀무가설을 기각하고 자신이 주장하고자 했던 대립가설을 채택할 수 있다
반대로 귀무가설을 틀렸다고 증명하는 방법으로 접근할 시, 유의확률이 그것을 넘으면 대립가설을 채택할 수 있다.
어떠한 사실이 틀렸음을 증명하려면, 주장과 반대되는 예를 하나만 찾으면 된다.
따라서 내 연구가 틀렸다는 주장이 틀렸음을 증명하면, 내 주장이 맞게 된다.
내가 주장하려고 하는 가설의 반대를 귀무가설로 설정하고, 그것이 틀렸음을 증명하면 나의 주장이었던
대립가설이 인정된다.
귀무가설이 맞다고 치고, 모은 자료가 일어날 확률이 정한 유의수준을 넘으면 기각, 자연스레 대립가설이 채택된다.
예) "백조는 희다"라는 귀무가설에 내가 주장하려는 대립가설은 "백조는 항상 희지는 않다"이다. 거기서 귀무가설의 유의수준(5%)을 정해두고, 유의확률이 그것을 넘었을때,(백조 예에서는 검은 백조가 계속 나와서5/100를 넘었을 때) "백조는 희다"라는 귀무가설은 틀리고, 자연스레 내 주장인 "백조는 항상 희지는 않다"가 맞게 된다.

맨 위의 가로선 : 최대값
사각형의 윗변 : 3사분위수(MAX에 가장 가까운 최빈값)
굵은선 : 최빈값
사각형의 아랫변 : 1사분위수(MIN에 가장 가까운 최빈값)
맨 아래의 가로선 : 최솟값
가설검정 분석모델(아래 PPT 참조)
사례 1:
K 회사는 기존에 고객만족도 점수가 평균이 8.6점이고 표준편차가 0.8점으로 알고 있었다. 그러나 최근 200명 고객을 대상으로 고객만족도 조사를 한 결과 평균 8.8점으로 나타났다. 이에 K 회사는 최근 조사를 바탕으로 기존에 알고 있던 고객만족도 평균이 8.6점이 아니라고 통계적으로 주장할 수 있는지 검증하고자 한다.
위의 사례에서의 분석 모델에 대한 가설을 설정해 본다.
이것의 귀무가설은?
이것의 대립가설은?
사례 1
고객만족도 점수의 평균은 8.6이다.
고객만족도 점수의 평균은 8.6이 아니다.
사례 2:
H고등학교 남자 선생님들은 결혼 후 살이 찐다고 주장하려고 한다. 이를 위해 H고등학교 소재의 다른 고등학교에 재직 중인 결혼한 남자 선생님들을 표본추출 하여 결혼 기간과 결혼 전후 몸무게 데이터를 구하여 분석하였다. 결혼 기간과 몸무게 증가가 상관관계가 있다고 할 수 있는지를 통계적으로 검증하고자 한다.
위의 사례2 에서의 분석 모델에 대한 가설을 설정해 본다.
이것의 귀무가설은?
이것의 대립가설은?
사례 2
결혼,교직은 비만과 관계가 없다.
남자 선생님은 결혼 후 살이 찐다.
설문지와 코딩하기 1문제
-측정 도구를 선택하는 데에서의 유의점
설문지 작성시 유의사항
설문지는 가설을 구성하고 있는 변인들을 측정하기 위해서 사람들에게 물어볼 질문들로 구성된다.
설문지의 질문들은 연구의 목적, 즉 가설을 검증하기 위한 질문에 초점을 맞추어서 작성되어야 한다.
신뢰성과 타당성이 확보된 측정도구를 선택해야 한다.
R언어-1 1문제
-패키지 설치 방법
-한글설정 방법
-프로그램 다루는 방법
패키지 설치하기
install.packages("패키지명")
패키지 불러오기
library(패키지명)
한글설정
단일 실행 : 콘솔에서 Ctrl+Enter로 한줄씩 실행
다중 실행 : 실행시키고 싶은 내용을 드래그후 Ctrl+Enter
R언어-2 6문제
기초사용법 다나옴
데이터 핸들링
벡터의 종류,우선순위
연산자,우선순위
벡터의 연산
데이터가 혼합되면 어떻게되는가
모두 여기에 정리되어 있다.
R언어-3 3문제
Factor matrix list dataframe의 특징들
행렬 생성, 뺐을 때 어떻게되는지(matrix 함수;rbind(row),cbind(col))
행렬의 개념-데이터종류 하나만:factor,matrix 여러개있는것:list,dataframe
행렬의 활용-패키지 활용, 뜻하는 것들이 뭔지
데이터셋의 특징은 여기로
library(help=datasets) ## R에서 제공하는 데이터 샘플
head(iris) # 꽃받침의 가로세로, 꽃잎의 가로세로, 품종(세가지)
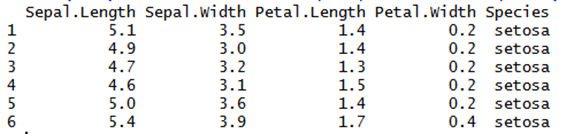
str(iris) ## 150개의 관측값, 5개의 변수

1.iris 데이터셋은 어떤 집단으로 구성되어 있는지 확인하세요
setosa, versicolor, virginica (붓꽃의 세가지 종) #head(iris$Species)를 통해 구할 수 있다.
2.iris 데이터셋에서 품종별 꽃받침의 가로 평균을 구하시오.
3.iris데이터셋에서 품종이 “setosa"이고, Sepal.Length>5 인 데이터를 조회하시오
4.iris데이터셋에서 품종이 ‘setosa’의 기초통계량을 구하시오
(Rstudio로 구해야함)
R언어-4 3문제
파일을 읽었을 때 그게 뭔지?? 그 파일이 뭘로 이루어져있나, 구조, 형식같은것
stringsAsfactor이 뭔지(옵션들에 대한 특징) header, sep, file--읽어오기
파일 쓰기에 대한 각각의 뜻-옵션
파일 읽기
A<- read.table("C:\Users","test.txt", header = TRUE, sep=",", stringsAsFactor=F)
라는 예가 있다.
A에 해당경로에 있는 text.txt를 읽은것을 카테고리 분류가 있는 상태로, 반점(,)으로 분류되어 있으며,
문자열을 factor형으로 반환하지 않았다.
라는 뜻이 된다.
head(A,n=10) A의 앞쪽 10줄을 읽어온다
tail(A,n=5) A의 마지막 5줄을 읽어온다
파일 쓰기
A <- write.table(USArrests,file = "US.csv", sep=",", row.names=F, col.names=TRUE)
A에 USArrests에서 읽은 US.csv를, 반점(,)구분으로, 가로이름은 안 읽고, 세로이름은 읽은 채로 파일을 쓰고 싶다.
라는 뜻이다.
예제
•kosis.kr(통계청) 사이트 접속
•국내통계 - 인구가구-인구동향조사- 인구동태건수 및 동태률추이(1970~2018)
•항목 : 조사망률, 합계출산율, 혼인건수, 기대수명체크 - csv로 다운로드
•Excel시트에서 행과 열을 바꾸고, 저장 ( demog.csv로 저장 )
•R로 ‘demog.csv’로 읽어 들인 후,
demog이라는 객체에 넣어주고, 아래와 같이 View(demog) 해 본다
demog <- read.csv("demog2.csv", sep=",", header=FALSE,stringsAsFactor=FALSE)
str(demog)
'data.frame': 50 obs. of 5 variables:
$ V1: chr "기본항목별" "1970" "1971" "1972" ...
$ V2: chr "조사망률(천명당)" "8" "7.2" "6.3" ...
$ V3: chr "합계출산율(명)" "4.53" "4.54" "4.12" ...
$ V4: chr "혼인건수(건)" "295137" "239457" "244780" ...
$ V5: chr "기대수명(출생시 기대여명)" "62.3" "62.7" "63.1" ...
names(demog) <- c("year", "cdr", "tfr", "marn", "leo") #이름 지정
demog<- demog[-1,] #1행 빼기
rownames(demog) <- NULL ## 행 머리글 빼줌
demog <- demog[-49,] ## 2018년도 빼줌
R언어-5 5문제
연속형, 범주형 변수
기초통계값 구했을 때의 특징들
양적변수를 파악하기 위한 쓰는 것들
그래프의 옵션들-2문제 그래프를 그리기 위해서 데이터가 어떤 조건으로 있어야 하는지
히스토그램, 바플롯의 데이터 조건 차이
한번 읽어보는 것을 추천한다. 그림덕분에 이해가 더 잘 될것이다.
R언어-6 0문제
-한 번 읽어만 본다. 따라서 정리 안함.
R언어-7 1문제
회귀직선(11번슬라이드)
회귀직선 구하기


구하는 이유는 무엇일까
- 많은 x,y데이터를 이용해 모르는 x에 대응하는 y값도 구해내기 위해서
lm함수를 이용한다.
예제
BMI <- read.table("BMI.txt", col.names=c("height", "weight", "year", "religion", "gender", "marriage"))
이제 이 정도 읽기는 쉽다.
여기서
plot(BMI$weight, BMI$height, main="남녀 키와 몸무게의 추세선")
하면 1번째 그림이 나온다.
그리고, lm(height~weight, data=BMI) 으로, y=ax+b 형태의 일차함수를 구한다.
일차함수를 그려주는 그래프가 abline이다
abline(lm(height~weight, data=BMI),lwd=2,col="green")
하면 lm으로 구한 그래프의 방정식으로 굵기 2의 초록색 그래프가 된다.

'CODING > [R] Big Data' 카테고리의 다른 글
| 003. R언어특(징) (0) | 2019.03.19 |
|---|---|
| 002. R언어 하는 법 (0) | 2019.03.15 |
| 001. START (0) | 2019.03.15 |


